Log Models¶
Model logging in MLflow refers to the practice of saving and tracking machine learning models during the development and experimentation process. When we log a model in MLflow, we save the model as an artifact in a centralized repository, allowing us to easily access and manage different versions of the model.
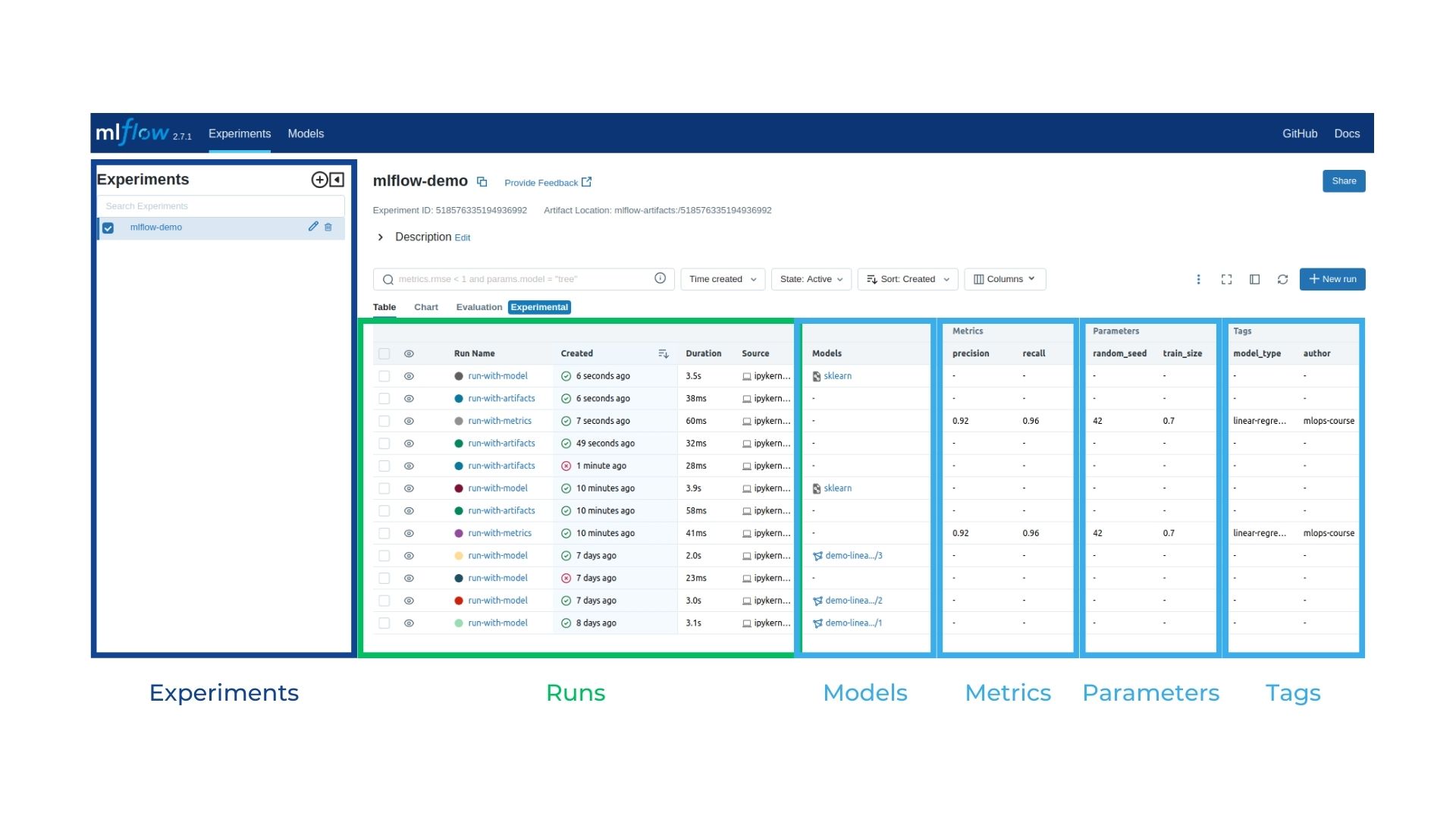
Model logging is important in MLflow for several reasons.
Reproducibility: Logging models ensures that we can reproduce our experiments later on. By storing the exact version of the model used during training, we can accurately reproduce the same results or compare different model iterations.
Collaboration: MLflow allows teams to collaborate effectively by sharing models. By logging models, team members can easily access and deploy specific versions of the model, making it simpler to work together on projects.
Tracking: Model logging helps in tracking the development and progress of the model. It allows us to keep a record of the model's performance, metrics, and associated metadata, making it easier to analyze and compare different iterations or approaches.
When logging a model we specify the library used to create the model model.<library>.log_model(). Specifying the library used to create the model when logging helps ensure compatibility and consistency. Different machine learning libraries may have their own formats and conventions for storing models. By specifying the library used, MLflow can appropriately handle the model serialization and deserialization process, ensuring that the logged model can be loaded correctly when it is later accessed or deployed.
In summary, model logging in MLflow involves saving and tracking machine learning models, providing benefits such as reproducibility, collaboration, and progress tracking. Specifying the library used to create the model ensures compatibility and consistency when storing and retrieving the models.
✨ Create a simple Model¶
A simple linear regression model trained on random data.
import numpy as np
from sklearn.linear_model import LinearRegression
# Mocked data
X = np.random.rand(100, 1) # Independent variable
y = 2 * X + np.random.randn(100, 1) # Dependent variable with some noise
# Create and fit the linear regression model
model = LinearRegression()
_ = model.fit(X, y)
💾 Log the model¶
import mlflow
mlflow.set_tracking_uri("http://localhost:5000") # ❗ set your tracking server URI
EXPERIMENT_NAME = "mlflow-demo" # ❗ make sure this experiment exists
RUN_NAME = "run-with-model"
experiment_id = mlflow.get_experiment_by_name(EXPERIMENT_NAME).experiment_id
with mlflow.start_run(
experiment_id=experiment_id,
run_name=RUN_NAME,
) as run:
# log the model
mlflow.sklearn.log_model(model, "linear_regression_model") # 👈 we tell mlflow is a sklearn model
mlflow.set_tags({"model": "linear-regression"})
# Print the run ID
print(f"Run ID: {run.info.run_id}")
Run ID: 585b6ec37839467d832d54b95886d6e9
✍️ Model Signature¶
The model signature is a description of the input and output data types and shapes of the model. It is used to ensure that the model is used correctly when it is later loaded and deployed. The model signature is specified when logging the model, and it is stored as part of the model metadata.
from mlflow.models.signature import infer_signature
# Infer the signature of the model
signature = infer_signature(model_input=X, model_output=y)
# Start a run to log the model with the signature
with mlflow.start_run(
experiment_id=experiment_id,
run_name=RUN_NAME,
) as run:
# log the model with the signature
mlflow.sklearn.log_model(model,"linear_regression_model", signature=signature)